library("rjwsacruncher")
cruncher_and_param(
workspace = "C:/my_folder/my_ws.xml",
rename_multi_documents = FALSE,
policy = "lastoutliers"
)Part 3: Infra-annual and annual campaigns
Infra-annual campaigns
The objective of an infra-annual campaign is to quickly produce an updated SA-CJO series when a new gross point is available and the recent past of the gross series may be revised. The seasonally adjusted series has two sources of revision: the raw data and changes to the final seasonal factor estimation models. The seasonal adjustment guidelines recommend minimizing these so-called technical revisions (see Chapter 6). A common method for achieving this objective is to use the predicted seasonal factors, including the predicted calendar effect, calculated during the last annual campaign. However, JDemetra+ also offers a continuum of refresh methods that allow to gradually loosen the constraints on the pre-adjustment and control the revisions of the linearized series before the decomposition step, which will be completely redone. All of these refresh policies are presented in the documentation 🔗, among which the “lastoutliers” option is particularly recommended. In this case, we allow ourselves to re-identify the outliers over the last year. Manual expertise in the infra-annual context will focus on revisions and therefore outliers, avoiding too many parameter changes. This refresh is possible from the graphical interface, with the Cruncher by specifying the “policy” argument of the rjwsacruncher::cruncher_and_param function but also directly in R, as shown in the code examples in the appendices 🔗.
For infra-annual estimation with the Cruncher, the following R code can be used:
Table 4: Implementation of a refresh policy
| Data type | Tools |
|---|---|
| Workspace | - GUI (Drop-down menus)🔗 |
- rjwsacruncher::cruncher_and_param(..., policy= ,) 🔗 |
|
- rjd3workspace::jws_refresh() 🔗 |
|
| TS objects in R | - rjd3x13::x13_refresh() 🔗 |
- rjd3tramoseats::tramoseats_refresh() 🔗 |
The use of forecast seasonal coefficients (\(S\_{f}\)) simply requires exporting them at the end of the installation process, then at the end of each annual campaign, in order to perform the calculation: \(Y_{sa}=Y_{raw}-S_{f}\) or \(Y_{sa}=Y_{raw} / S_{f}\), in the case of a multiplicative model. To potentially take into account a revision of the recent past of the raw series, exporting past coefficients is also useful. The series of forecast coefficients can be generated by the Cruncher by specifying it in the options, as shown below
options(default_tsmatrix_series = c("sa", "sa_f", "s", "s_f"))or in R by defining a user-defined output as shown below
mod <- x13(y, userdefined = c("s", "s_f"))
str(mod$user_defined)Annual campaigns
An annual campaign consists of updating seasonal coefficient estimation models to verify that the parameters used do indeed produce seasonally adjusted series with the required properties (absence of residual seasonality, absence of residual calendar effects, etc.).
This update can be done by comparing the current or reference models used up to the time of the campaign with an automatic estimate. In most cases, the automatic estimation will be constrained by past parameters such as the selection of calendar regressors or certain pre-specified outliers, particularly those from the COVID period. For ease of comparison, it may be useful to calculate the quality report scores described in Part 2 for the “reference” or “current” workspace and the “automatic” workspace. A lower score for the automatic estimate means that this is preferable, and a new workspace (“working”) can then be created by merging the “current” and “automatic” workspaces, as detailed in the appendices 🔗.
This approach requires working on comparable raw series. If these have undergone significant revisions (re-basing, change of source, etc.), we return to an approach similar to the installation of a new process.
Main steps:
Update the reference workspace (“ref”) using the new raw data and statistical parameters from the previous annual campaign, possibly modified by the same strategy as a sub-annual campaign (e.g., “lastoutliers”).
Automatic estimation (“auto”) on the new raw data, probably maintaining certain parameters (set of calendar regressors, some or all of the outliers “pre-specified” by the user, etc.)
calculation of scores for the two workspaces “ref” and “auto”
merging of the “auto” and “ref” workspaces into a new ‘working’ workspace according to the score value of each series
editing of a quality report on the “working” Workspace
Manual review with selective editing, as in the installation phase
Generation of the final output with the Cruncher, as in the installation phase
If forecast coefficients are used during infra-annual campaigns, the workspace from the previous annual campaign can be updated with a policy “last outliers” to return to the case described above.
Details on how the data is organized and code snippets are provided in the vignette {rjd3production} package 🔗.
Numerical impact of a change in parameters
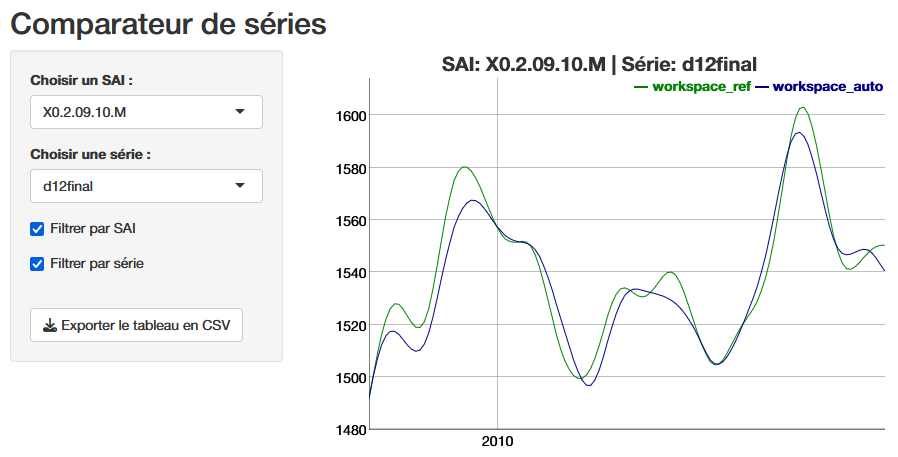
In light of the (bad) diagnostics, identified in particular through the quality report, the producer can intervene to modify the parameters and improve the statistical quality of the adjustment. For example, they can modify a set of calendar regressors and eliminate the residual calendar effects that they had previously observed. Beyond improving statistical test results, it is often useful to visualize the numerical impact of a parameter change or re-estimation, which allows revisions to be quantified and visualized, but also certain settings to be validated, particularly the choice of outliers based on “expert knowledge.” Exporting the series produced is one solution, but if you want to make these comparisons before you have finished working on a workspace, you can use the compare() 🔗 function from the rjd3production package, which avoids generating intermediate outputs. This allows you to read the series directly in two or more workspaces, each corresponding to a version of the parameters or a state of the estimate, as shown in the following code:
df <- compare(path_ws_ref, path_ws_work)
run_app(df)The function launches a shiny application that provides a graphical comparison, below is the final trend (d12), and the ability to download the series values to analyze the revisions.
Conclusion
Ensuring the statistical quality of seasonally adjusted series requires the implementation of a production process that, in light of diagnostics, allows for easy and large-scale customization of estimation parameters. The use of the open-source software JDemetra+ and its numerous R tools makes it possible to achieve this goal by offering many automation options while providing access to detailed manual fine tuning. We have seen that the decision to integrate the graphical user interface into a production process is fundamental to the organization of data. The main reasons for this should be the use of manual expertise and performance. However, an organization based solely on R does not exclude ad hoc use of the GUI or Cruncher. The organization of operations and the use of tools as described in this article are, of course, only suggestions, which we hope will provide practical answers to the many producers of SA series who wish to use JDemetra+.
In order to communicate with their users, they often need reporting tools that break down the effects of seasonal adjustment on changes in a given series, in particular to highlight the various contributions to revisions. Such tools are often very local, but there are packages or plug-ins linked to JDemetra+, often still in version 2, that allow this type of information to be obtained quickly. It would be interesting to follow up on this article by offering a review of open-source reporting tools and making available an R package that allows users to take full advantage of version 3 of JDemetra+.